%20Complete%20Guide%20to%20Data%20Center%20Redundancy-1.png)
There’s no way to sugarcoat this: a data center going dark can result in damages worth millions. Whether it’s a niche enterprise with an on-premise data center or a business exclusively providing data hosting services, keeping those servers running around the clock is not an option but a necessity. And that’s where data center redundancy comes in to save the day!
Data centers face multiple threats that can result in downtime, from socially engineered human errors to sophisticated ransomware attacks. Hardware and power supply failures are also among the causes. However, hardware and power failure risks can be mitigated with infrastructure redundancy.
80% of data centers reported outages in the last three years, according to the Uptime Institute’s Data Center Resiliency Survey in 2022. Of those, 43% resulted from uninterruptible power supply (UPS) failure.
This article dives into data redundancy, listing different levels and making a case for why you should readily invest in making your data center redundant.

What Is Data Center Redundancy?
Data redundancy refers to provisioning duplicate or extra (redundant) hardware, such as power supplies, servers, or storage, to prevent downtime and unavailability in case of failure.
The redundant infrastructure typically comprises critical assets necessary for operations to keep running. Simply put, redundant data centers keep duplicate assets on hand to swoop them in just in time to prevent a total outage.
As data center redundancy is essential, the industry has developed different levels of redundancy that companies can adopt. This is because different data centers require different levels of redundancy. A small data center handling retail workloads may not require the same redundancy as a data center handling financial services.
Data Center Redundancy Levels Explained
The various data center redundancy levels have different outcomes and costs. The gist is the higher the redundancy, the higher the cost. Selecting the appropriate level requires an analysis of your risk tolerance and, of course, your budget. Similarly, it may also depend on any service level agreements (SLAs) with your users and regulations that apply to your company.
| Red. Config. | Reliability (normal) | Reliability (maintenance) | Capital Cost | Operating Cost | Complexity | Foot Print |
| N | 4 | 2 | 10 | 8 | 10 | 10 |
| N+1 | 6 | 4 | 8 | 9 | 9 | 9 |
| N+2 | 6 | 5 | 6 | 8 | 9 | 8 |
| 3N/2 | 8 | 5 | 5 | 6 | 2 | 5 |
| 2N | 9 | 6 | 3 | 4 | 5 | 4 |
| 2(N+1) | 10 | 9 | 2 | 2 | 4 | 2 |
Before we discuss the different levels, let’s first discuss ‘N.’
N represents the minimum number of a particular device to do its job in the data center.
Here’s an example: a data center with eight servers requires two UPS units to power all the servers. The N for UPS would be two, whereas it would be eight for servers.
N is essentially the bare minimum equipment required to keep the operations running at full capacity.
Here are four levels of data center redundancy:
N+1
The N+1 redundancy level stipulates that the data center has the minimum capacity for a device or system and an additional one to take place if one of them fails.
Expanding on the above example, an N+1 redundancy level for this particular data center would require nine servers and three UPS units. If one server fails, there’s one more available to take its place. Similarly, if one UPS fails, there’s another to replace it.
This is good but perhaps not the best. What if another server fails? In such a case, operations would still run, just not at full capacity.
2N
2N redundancy essentially means doubling/duplicating the minimum capacity. In other words, there’s a spare to replace the particular device or system.
Again, considering the above example, a redundancy of 2N would mean 16 servers and four UPS systems. While the eight servers and two UPS units would remain operational, each of these operational units would have a spare to replace them in case of failure.
2N level is arguably the most risk-averse but also the most expensive. Nevertheless, a 2N-level redundant data center is more resilient than N+1.
2N+1
2N+1 is the highest level of redundancy that combines 2N and N+1. It duplicates the entire minimum capacity and adds one more on top.
So for the data center example above, a 2N+1 redundancy would look like this: eight servers with nine spares and two UPS with three spares.
While this level of redundancy for critical assets like power supply and cooling is highly reliable, it’s incredibly expensive. It can ensure the data center keeps running smoothly even if all the operational units fail, and even a spare does.
3N/2 (Distributed)
3N/2 or three-to-make-two is a distributed redundancy close to 2N but not nearly as expensive. This configuration uses load management, which can add some complexity. It’s suitable for power supply and cooling systems.
This redundancy distributes capacity into multiple smaller units to reduce costs for duplication.
Benefits of Data Center Redundancy
While 2N and 2N+1 levels of redundancy ensure more resilience, redundancy at any level and form is necessary. There are obvious advantages, like outage prevention, but some benefits are more nuanced.
Increased Reliability
A redundant data center is reliable and can live up to its uptime guarantee and, more importantly, availability claims. With critical infrastructure components like power supply and cooling backed up with spares, outages can be avoided when push comes to shove.
However, redundancy doesn’t have to be limited to power supply or cooling systems. Data centers, particularly those that frequently have to handle spikes in data usage, should also consider making servers and storage redundant.
If a server fails and there’s one readily available to replace it, you can ensure you’re running at full capacity throughout. That ensures higher availability, which may be even more important than uptime.
Better Uptime and Availability, Higher Data Center Tier
There are four tiers of data centers. While these tiers are based on the data center's uptime, redundancy directly impacts tier ranking as it determines uptime. A more redundant data center is less likely to experience downtime and attain that near-perfect 99.995 percent uptime to qualify for the highest tier.
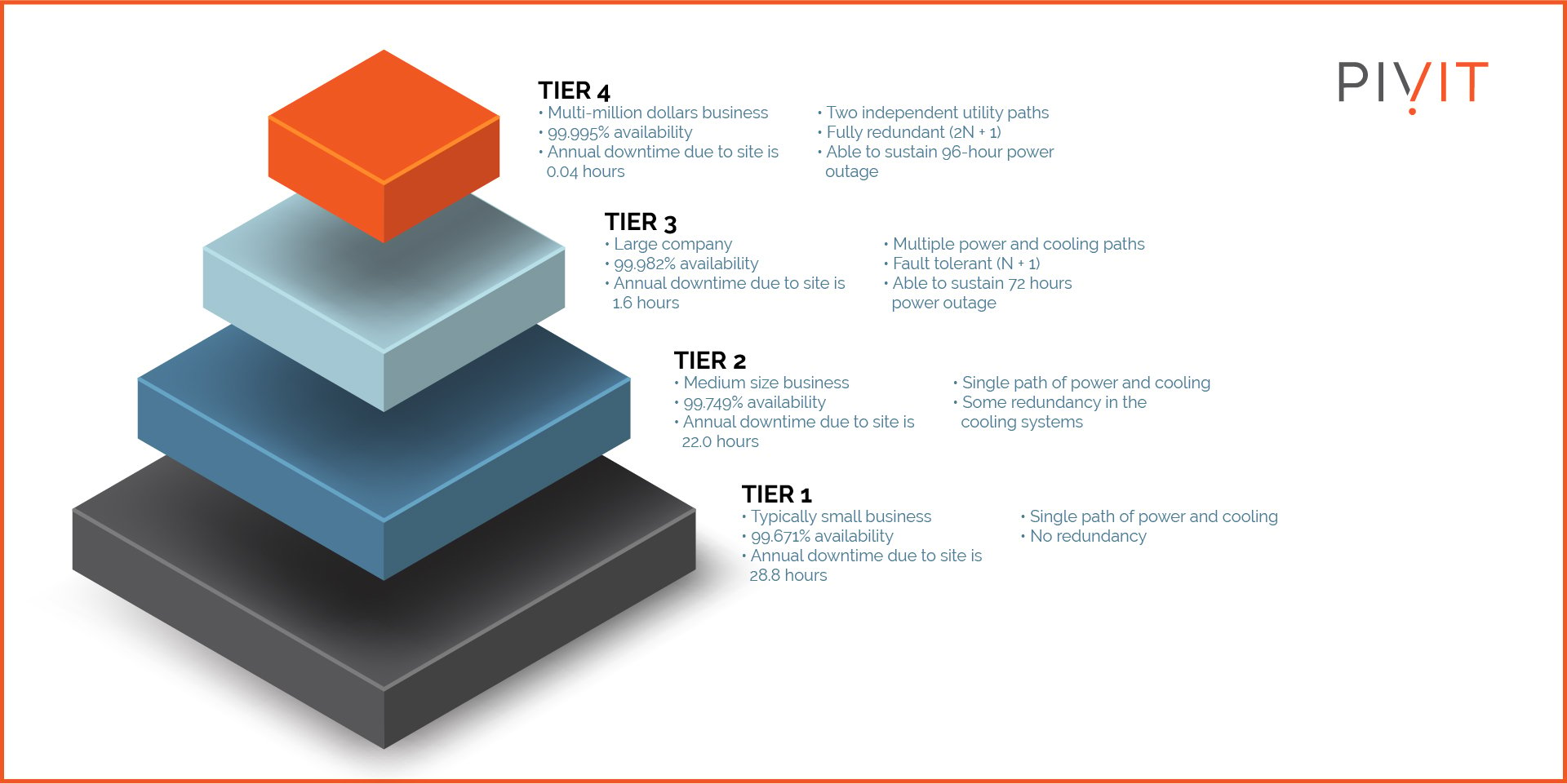
The higher tier is good for the company's reputation and can double as a marketing strategy to attract leads.
Rely on Our Sparing Integrity Program!
While most data centers invest in spares for essentials like power supply systems, redundancy can be taken one step further by having spares for critical network equipment.
Suppose a server develops a fault that may take weeks to be fixed. That means, for that entire week, you can expect to run below capacity, which directly impacts the availability of compute and storage resources. Now, if you were to have a spare for that particular server, it could be swapped in its place, and voila, it’s like nothing happened. Your operations are running at full capacity, and your users face no disruptions.
You can achieve that with the help of PivIT’s Sparing Integrity Program.
Unlike other third-party maintenance providers, PivIT guarantees your spare with its program. Not only do you know you have a dedicated spare, you know where exactly it exists. And when the time comes, the spare shall be at the location within the SLA of your contract, which can be as quick as four hours.
So if you’re looking to make your data center resilient and reliable through effective redundancy, consider having critical spare hardware with the help of PivIT. When your primary hardware fails, you can be sure its replacement is already on its way.
