
Stable behavior and high network availability is every network engineer’s goal.
It provides many benefits to the overall enterprise’s internal operations and prevents undesired results, such as unplanned downtime that can quickly lower employee productivity and cause financial losses.
Those losses can be significant: at one point, Gartner reported that most companies reported downtime costs of as much as $100,000 to $540,000 per hour.
However, as much as IT personnel tries to eliminate any active or potential problems, the networks will never be perfect, and issues will always arise. Once the problem is reported by a user, the troubleshooting process starts.
In this article, we will provide the following:
- An overview of the troubleshooting concept.
- An overview of network troubleshooting procedures.
- An exploration of the troubleshooting methods.
- Familiarization with the most commonly used troubleshooting tools.
Not what you were looking for today? View some of our popular articles:
- Back to the Basics: Is Static or Dynamic Routing Better?
- What Is Public Key Infrastructure and How Important Is It?
- The 2023 Guide for Everything Related to the AAA Framework
The Many Faces of Troubleshooting
The biggest network paradox is that when a network is correctly installed and properly configured, it should continue to operate without any problems in the future.
However, as much as it makes sense, the outcome is completely different in real life. And this leads to one very famous quote, “In theory, there is no difference between theory and practice; in practice, there is.”
The thing is that a lot of unpredictable things can happen at any moment, such as cabling becoming damaged or a device getting misconfigured. All of that will cause certain problems.
Sometimes the problems exist even from the very beginning, after the initial device configuration, however, they are not discovered until later when a user tries to do something, and the network does not respond correctly.
Therefore, it is safe to say that the problem does not exist until it is noticed and reported. Once that happens, the troubleshooting process starts.
One of the biggest challenges in troubleshooting is that the process itself is very unpredictable, and you never know how simple or difficult it will be to find and solve the problem, or how much time you will spend working on it.
At the same time, you can approach the troubleshooting process in many different ways, because there are no specific recipes for troubleshooting. Ultimately, it is up to you to choose the most appropriate troubleshooting approach to solve each problem that will arise.
Since troubleshooting can be a very time-consuming process, applying the best method will greatly reduce the amount of time spent. Therefore, it is crucial to understand the troubleshooting process and everything that comes along with it, so that when you face problems, you always solve them most efficiently.
Network Troubleshooting Procedure
The troubleshooting process consists of several phases, each responsible for performing different actions. The movement through the phases defines the troubleshooting method, and although all methods eventually solve the problem in the end, not all are equally efficient in every situation.
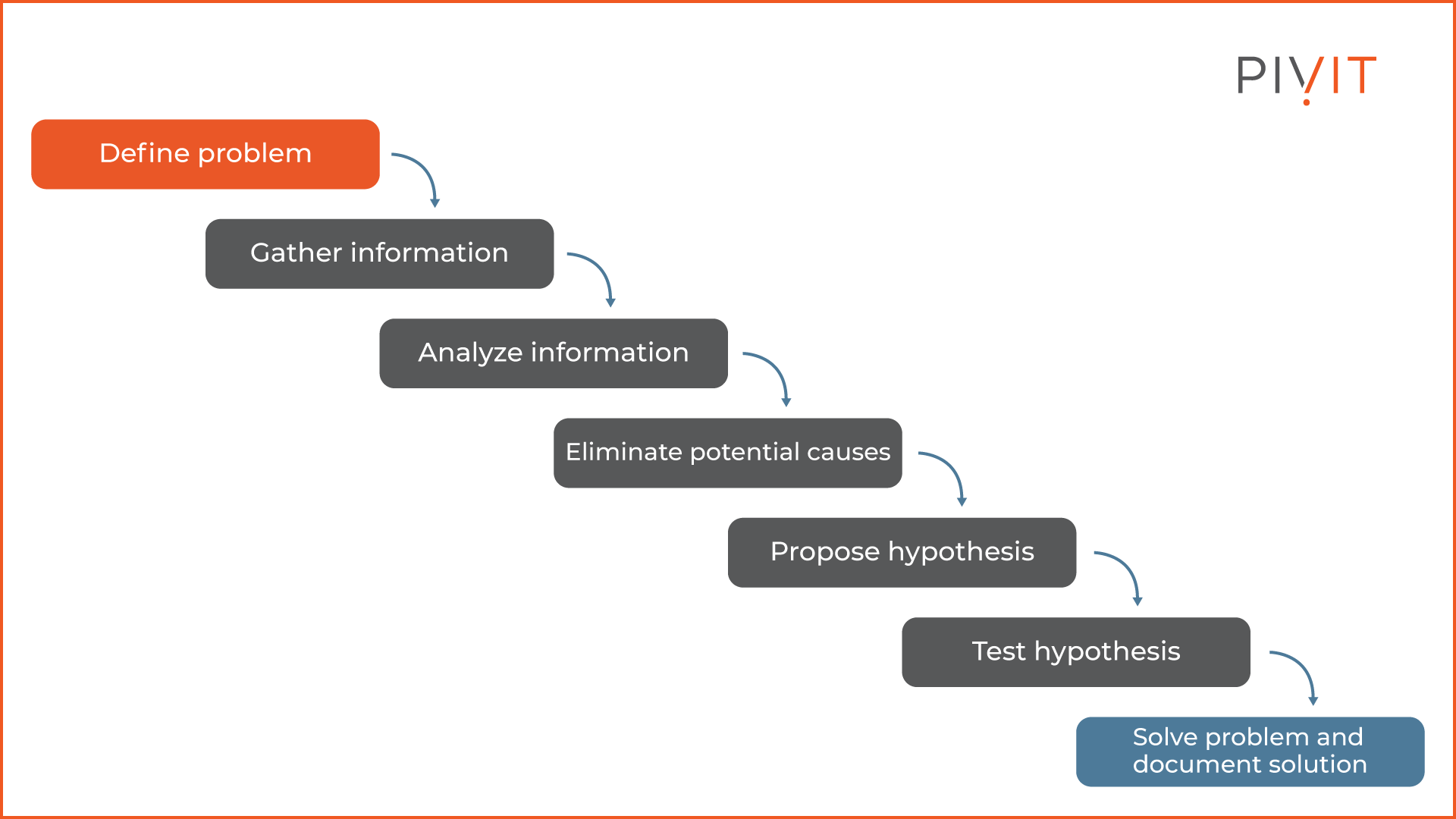
The first step in troubleshooting is to define the problem. This happens when a user reports that something is not working properly, such as being unable to access an internal server, open web pages, or anything else.
After the problem is defined starts, the process of performing diagnostics and most of the troubleshooting time is spent here. First, you must gather as much information as possible about the problem. Such information would be about the time when the problem was first noticed, whether the user did something that might have caused that problem, et cetera.
In the next phase, all that information is analyzed to get a better picture of the problem and think about what might have caused the problem. The time that you will spend on this phase depends on the amount of information gathered, and you might come up with several potential causes for the reported problem.
_________________
Are lead times slowing you down and preventing you from getting the firewall hardware or services you require to protect your data center? Send us a request or connect with our Team in real-time using our chat feature. Know what you want but need help configuring your setup?

_________________
The Most Important Phase
The next phase is the phase where you need to eliminate all potential causes so that you will focus only on the real ones. Because of that, this phase is the most important one in the whole troubleshooting process. If you misjudge and eliminate the real cause, you will continue the troubleshooting process working on causes that have not caused the reported problem.
As a result, you will spend a lot of time troubleshooting based on incorrect information, which will not provide any positive feedback in the end. Therefore, you will have to go back into the troubleshooting process and repeat the same steps and hopefully not eliminate the real cause again.
Once all potential causes are eliminated except the real one, you must propose a hypothesis to solve the problem. To verify the hypothesis, you need to test it, and the only way to do it is to apply the solution in practice. If the hypothesis solves the problem, you need to document it, so you or other administrators will have guidance on approaching the same or similar problem in the future without going through the whole process again.
Keep in mind that the time one troubleshooter spends on each phase and how he/she moves from phase to phase can be significantly different from person to person. This is what separates rookies from expert troubleshooters.
The Variety of Troubleshooting Methods
Because several different structured troubleshooting methods exist, choosing the appropriate one for a reported problem is of essential importance. This will shorten the amount of time spent and solve the problem most effectively. There are six most commonly used troubleshooting methods.
Top-down
This method starts from the application layer in the OSI model and moves down to the physical layer. It is recommended in situations where the potential cause is software or application based. For example, the Windows OS is making an update, and the user starts experiencing problems afterward.
Bottom-up
This method is the opposite of the Top-down method and starts from the physical layer in the OSI model and moves up to the application layer. It is perfectly suited for situations where a physical cause might be the reason for the reported problem, such as cabling replacements or adding new devices.
Divide and Conquer
One of the most popular methods among troubleshooters. It starts in the middle of the OSI model, on the Network layer. It is based on ping, and depending on the result, the troubleshooting process focuses on the layers above or below.
Follow the Path
This method focuses on the path that the packets take when they travel throughout the network. This method can be very useful in scenarios where the network is complex and consists of many devices, so by performing a traceroute, you can find the device causing the problem because the traceroute will stop there.
Perform Comparison
Sometimes, devices can have similar configurations, and it can be used as an advantage in certain troubleshooting scenarios. By comparing the configuration on the device that has the problem with the configuration of a fully functional device, you can easily find the missing commands or any misconfiguration that has been done.
Swap Components
In some rare situations, the hardware of the device could be the reason for the reported problem. Although it is very unlikely to happen, it is still possible for the RAM memory or the flash drive to fail from time to time.
Troubleshooting Tools
Many different tools can be used on network devices during the troubleshooting process. Although they all provide useful information, depending on the problem, one or another will always be a better fit.
Logging is a very simple, yet very beneficial service for learning what has happened on the devices in the past. By default, syslog is enabled on Cisco devices, and it is recommended to export all log messages to an external syslog server for centralized monitoring.
In addition, to verify end-to-end connectivity, you can use several basic tools:
- Ping: A successful ping to an IP address verifies that there is basic IP connectivity between the hosts.
- Traceroute: This can help you to find out how far the data can reach the path toward the destination.
- Telnet/SSH: Both network communication protocols can be used to test if certain TCP or UDP ports are open on a specific host.
_________________
Hardware Options For You
Here at PivIT, we know the importance doesn't stop with the device itself. It stretches to what is available today, financing options, and more. We make it easy for you to find the hardware to build your network on your terms.

_________________
The Trickiest of All
As much as nobody wants to perform troubleshooting, it is the only way to solve the reported problems in the network.
However, unlike the implementation and configuration of the network, which is always predictable when it comes to time and resources, the troubleshooting process is unpredictable, and it can last from a few minutes to several hours, days, weeks, or even months in some rare cases.
Therefore, understanding the basics, and using the most appropriate method can result in more efficient troubleshooting. Use this guide to ensure you don’t run into any problems!